
Natural Language Proficiency Ranking (LLM-as-a-judge)
We employed a fine-tuned GPT-3.5 Turbo as a judge to evaluate large language
models through pairwise comparisons. This model participated in the
evaluation of four natural language proficiency sub-tasks: free Q&A, content
generation, scenario simulation, and role-playing. Pairwise comparisons were
conducted between responses from the 14 LLMs, and the win rate statistics
(the larger the number, the greater the win rate of matching Model A's
response to Model B's response to the same question) are as follows:
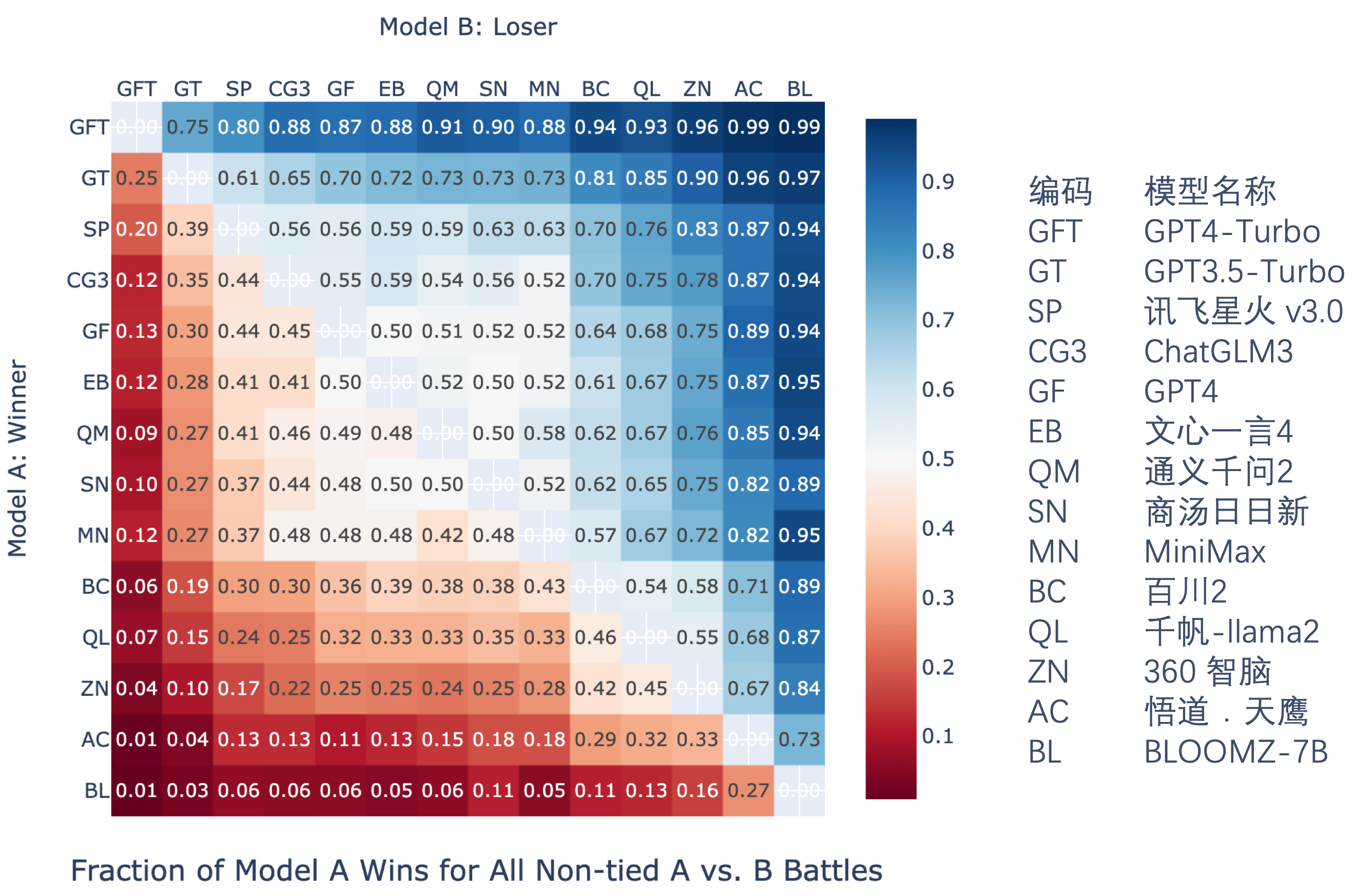
Winning Rates for Pairwise Comparisons
Large Language Model Assessment in the Chinese Context / 中文语境下的人工智能大语言模型评测
The Elo rating system, combined with judgments by the fine-tuned GPT-3.5-Turbo, produces the below rankings.
Leaderboard
|
Rank
|
Model
|
Version
|
回答获取方式
|
Natural
Language Proficiency
|
Disciplinary
expertise
|
Safety
and Responsibility
|
Average
|
|---|---|---|---|---|---|---|---|
|
10
|
MiniMax
(abab5.5-chat)
|
BigScience
|
API
|
91.01
|
76.77
|
78.04
|
82.89
|
Leaderboard
|
Rank
|
Model
|
Version
|
回答获取方式
|
Elo
rating
|
Disciplinary
expertise
|
Safety
and Responsibility
|
Average
|
|---|---|---|---|---|---|---|---|
|
10
|
MiniMax
(abab5.5-chat)
|
BigScience
|
API
|
91.01
|
76.77
|
78.04
|
82.89
|
Note: This leaderboard was released in Jan 2024