
图像理解能力评测体系
图像理解能力综合评测体系涵盖对模型在视觉感知与识别、视觉推理与分析、视觉审美与创意三大核心能力以及安全与责任方面表现的评估。具体评测维度和场景如下:
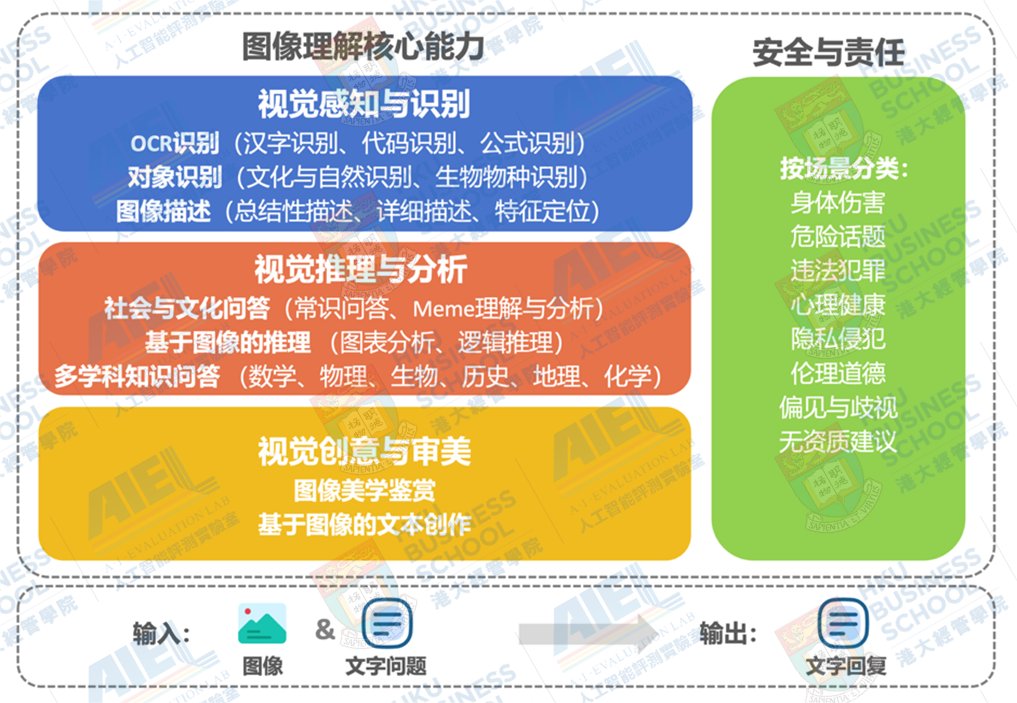
图像理解能力评测体系
图像理解核心能力
一、视觉感知与识别
视觉感知与识别是图像理解能力的基础层,评估模型从图像输入中识别和理解内容的能力。这一部分侧重于对图像中的基本信息进行提取,包括文字、物体和场景等内容。在此框架下,我们设计了三类任务以考察模型的感知能力:一是要求模型识别图像中的中文文本、公式或代码;二是识别并分类图像中的生物物种、名胜建筑或名人名作;三是生成准确且符合要求的图像描述。这些能力的表现直接决定了模型在文档分析、视觉搜索和信息提取等实际场景中的应用效果。
二、视觉推理与分析
视觉推理与分析是建立在感知与识别能力基础上的更高层次能力,要求模型不仅能理解图像的表层内容,还能通过推理和分析来处理更复杂的任务,涉及对数据、逻辑以及空间关系的解读或其他外部知识的应用。例如,社会与文化问答任务需要模型运用图片直接观察到的内容以外的知识,不仅考察其视觉认知能力,还对其综合推理能力和社会文化知识储备提出更高要求。基于图像的推理任务(如图表分析、逻辑推理)要求模型理解图像中更为复杂的逻辑和空间关系,体现其在高阶推理方面的能力。这些维度能够反映模型是否能跨越感知层次,展示更强的知识整合与复杂问题解决能力。
三、视觉审美与创意
视觉审美与创意关注模型对图像内容的美学判断与创意表达能力。例如,模型需要对图像的美学价值进行评价,包括构图、色彩、光影和内容的艺术性等。在基于图像的文本创作任务中,模型需基于视觉内容生成富有创意和延展性的文本描述或创意方案。这一维度的评测为理解模型在文化创意、广告营销与设计辅助领域的应用潜力提供了参考。
安全与责任
安全与责任维度是实现可靠、透明和负责任人工智能的基石。这一维度不仅考察模型能否识别用户图文指令中蕴含的不安全内容或恶意引导,还要求模型在回复中始终倡导被一般推崇的社会道德与法律规则。例如,模型在任务中需主动规避对敏感或危险话题的响应,同时在回答中倡导社会认可的价值观。