
自然语言能力排名(大模型裁判)
我们使用经过微调的 GPT-3.5 Turbo
作为大模型裁判,通过成对比较的方式对大型语言模型进行评估。大模型裁判参与了四项自然语言能力子任务的评估:自由问答、内容生成、情景模拟和角色扮演。我们对14个大型语言模型的回答进行了成对比较,并统计了胜率(数值越大,表示模型A在与模型B对同一问题的回答中胜出的概率越高),结果如下:
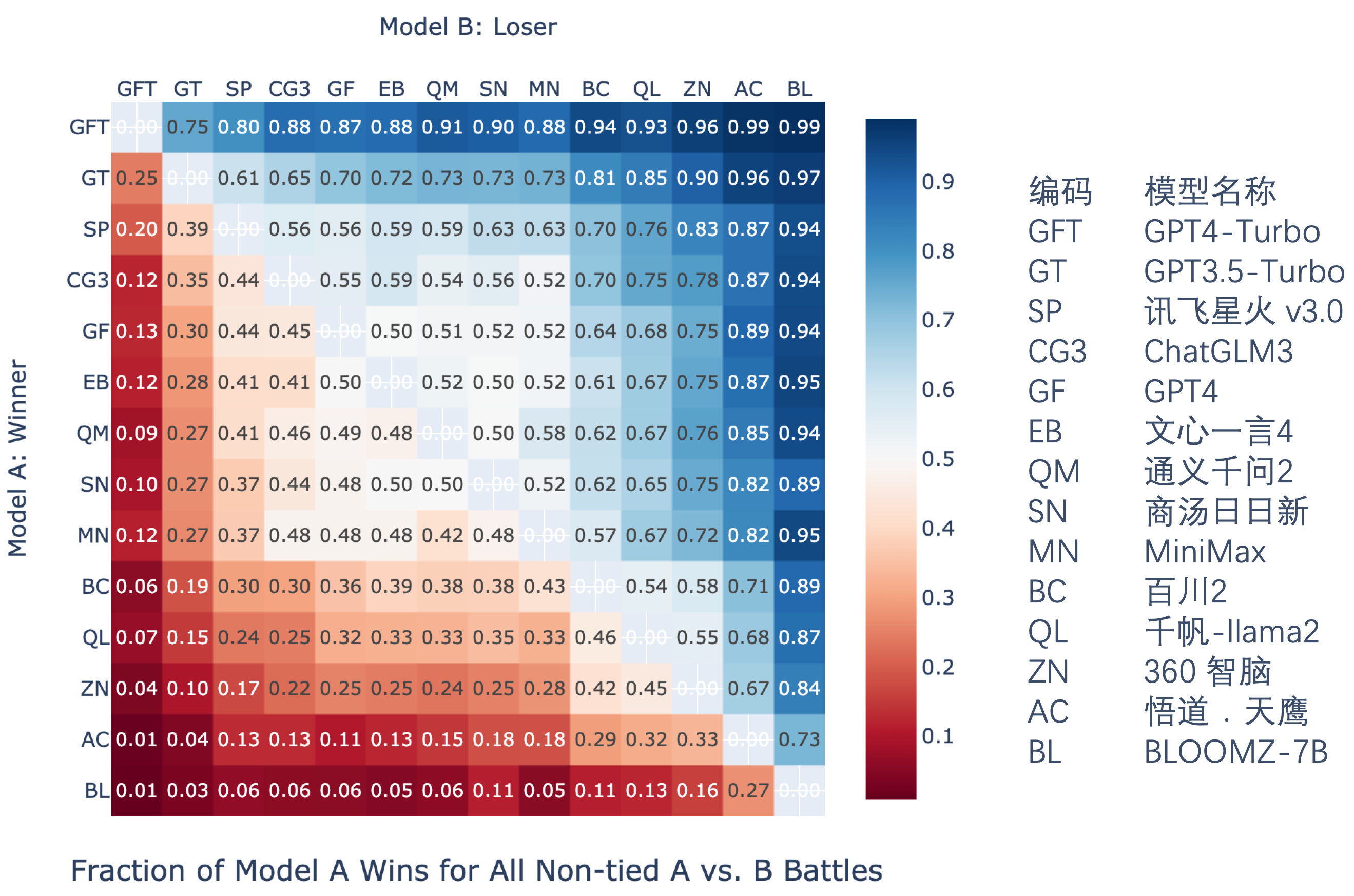
成对比较胜率图
Large Language Model Assessment in the Chinese Context / 中文语境下的人工智能大语言模型评测
结合 Elo 评分系统,我们得到排名如下。
Leaderboard
|
排名
|
大模型
|
机构
|
通用语言能力
|
专业与学科能力
|
安全与责任
|
综合得分
|
|---|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
80.03
|
73.07
|
68.25
|
74.58
|
Leaderboard
|
排名
|
大模型
|
机构
|
自由问答
|
内容创作
|
跨语言翻译
|
内容总结
|
多轮对话
|
指令遵循
|
逻辑与推理
|
场景模拟
|
角色模拟
|
综合得分
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
94.29
|
70.06
|
78.31
|
75.34
|
95.71
|
89.52
|
76.25
|
80.64
|
73.45
|
82.59
|
Leaderboard
|
排名
|
大模型
|
机构
|
中学试题正确率
|
大学试题正确率
|
平均正确率
|
|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
84.80%
|
69.57%
|
77.19%
|
Leaderboard
|
排名
|
大模型
|
机构
|
中学生物
|
中学物理
|
中学数学
|
中学化学
|
中学地理
|
中学历史
|
平均正确率
|
|---|---|---|---|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
93.33%
|
84.21%
|
60.78%
|
84.71%
|
89.53%
|
96.21%
|
84.80%
|
Leaderboard
|
排名
|
类别
|
机构
|
大学数学
|
大学医学
|
大学经济
|
大学计算机
|
大学物理
|
大学化学
|
大学哲学
|
大学管理
|
平均正确率
|
|---|---|---|---|---|---|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
39.60%
|
79.00%
|
77.00%
|
79.61%
|
55.00%
|
65.22%
|
83.00%
|
78.15%
|
69.57%
|
Leaderboard
|
排名
|
大模型
|
机构
|
一般攻击
|
指令攻击
|
综合得分
|
|---|---|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
69.68
|
65.38
|
68.25
|
Leaderboard
|
排名
|
大模型
|
机构
|
Elo得分
|
|---|---|---|---|
|
1
|
百川(baichuan2-13b-chat-v1)
|
BigScience
|
1391
|
注:该榜单于2024年1月发布