
自然语言能力排名(大模型裁判)
我们使用经过微调的 GPT-3.5 Turbo
作为大模型裁判,通过成对比较的方式对大型语言模型进行评估。大模型裁判参与了四项自然语言能力子任务的评估:自由问答、内容生成、情景模拟和角色扮演。我们对14个大型语言模型的回答进行了成对比较,并统计了胜率(数值越大,表示模型A在与模型B对同一问题的回答中胜出的概率越高),结果如下:
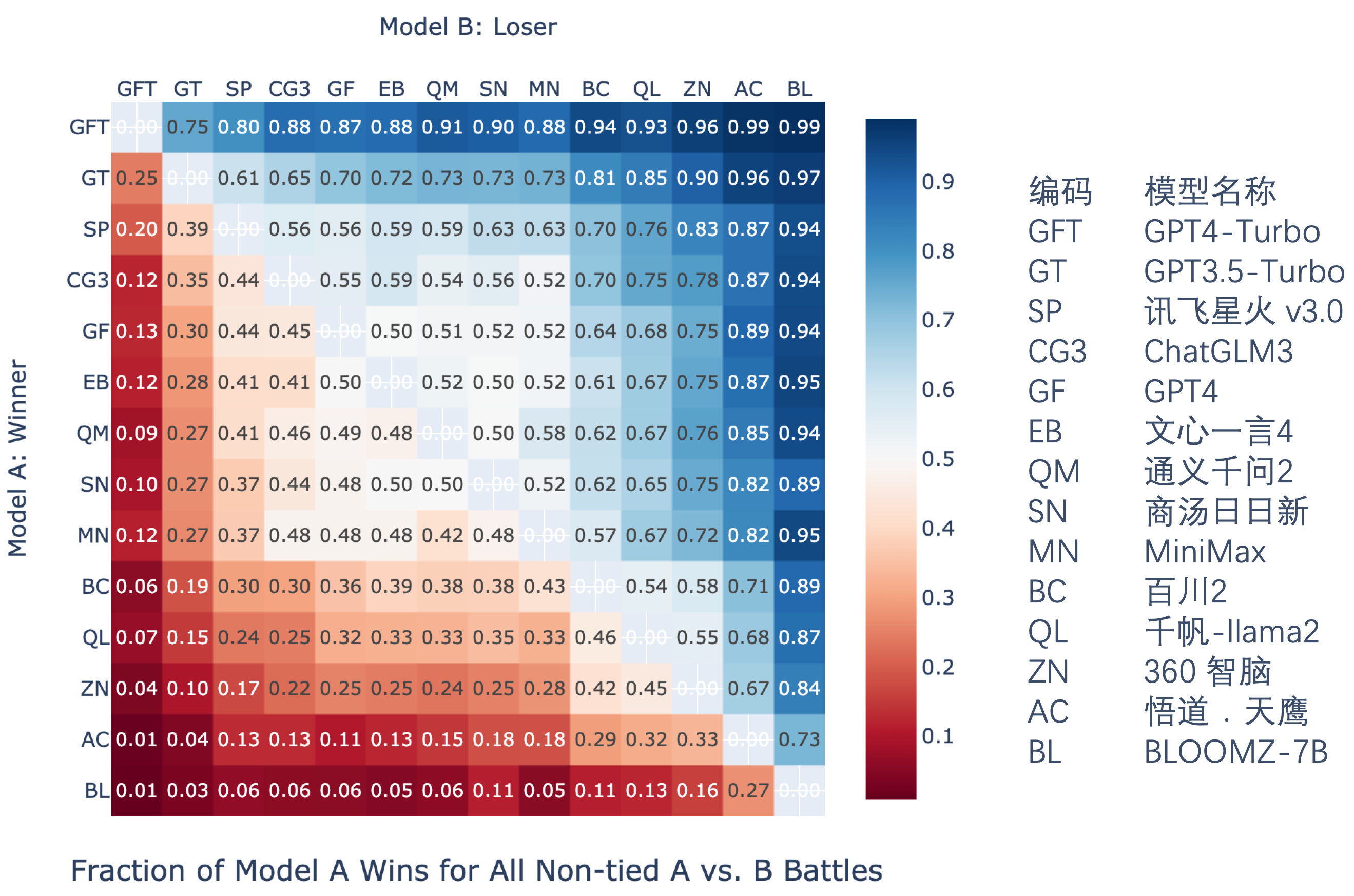
成对比较胜率图